When conducting my research on Keyframe reduction, my main starting point was the algorithm Salient Poses from a SIGGRAPH Asia Technical Brief (Optimal and Interactive Keyframe Selection for Motion Capture, Richard Roberts, J.P. Lewis, Ken Anjyo, Jaewoo Seo, and Yeongho Seol, SA 2018). In this article I will explain briefly what it is and how it works. For the point of view of the main author of the paper, please go check here
TL;DR
If you don’t have time, here is a quick summary of the algorithm:
Input: An animation (motion capture data -> curve in high dimension) plus an error function (takes a set of keyframes and computes how close the interpolation is from the real animation)
Output: the best set of exactly k frames for reconstructing the animation (for every possible k) aka the optimal set of k keyframes
How?: we use Dynamic Programming by iterating on the length of the animation! (First we make it stop at frame 2, then we push it further and further until we covered the whole animation) Complexity is polynomial.
Motivation: what do you mean by ‘Salient’?
Saliency is quite an important notion (and still so hard to describe properly) in data sciences and particularly in Computer Vision -I’ll try to write an in-depth article about that when I get some time.
Saliency is related to human cognition: the salient elements are the ones that attract the attention. For example, in an image, the salient element will be the closest object, in a video it will be the moving objects etc. such that it is easy to mistakingly think that Saliency boils down to object detection.
In animation, we see our animation as a curve -try to think of it as a motion trail- our goal is to find the Salient points of this curve which would be the most ‘notable’ points of the curve. The main goal of the paper is to perform keyframe reduction: from a motion capture input where there are keyframes everywhere, Salient Poses can reduce drastically the number of keys (keeping only 10%) without significant error in the animation such that the animation will be more convenient to edit.
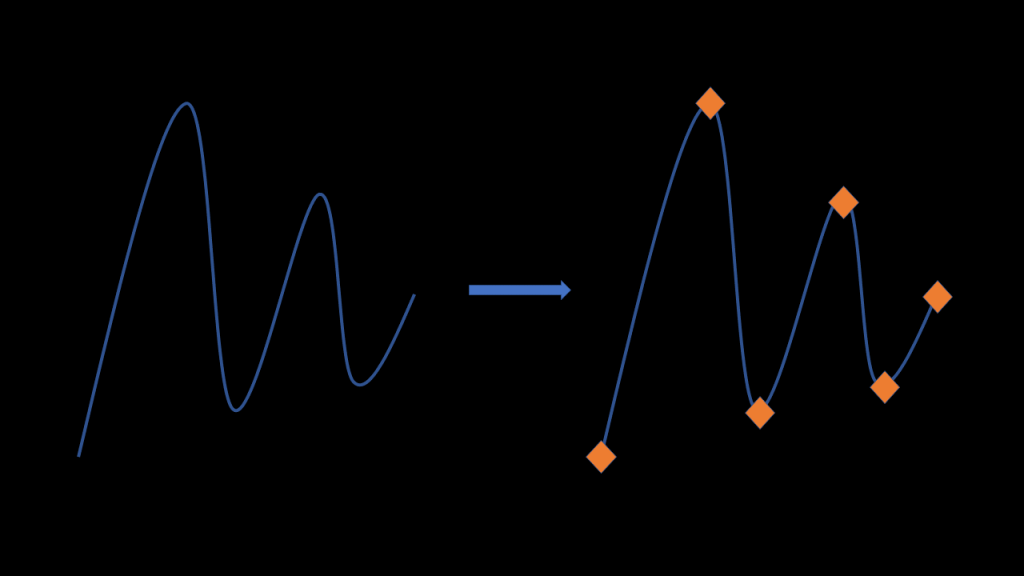
An animation as a high-dimensional curve
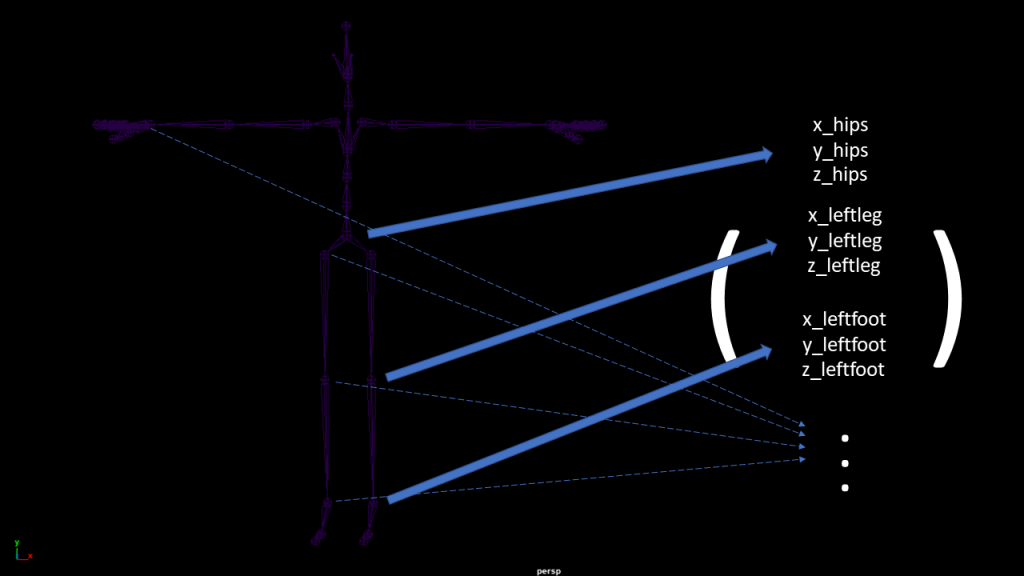
First of all, the algorithm treats the animation as a ‘high-dimensional’ curve. Let’s start simple and imagine I am considering a simple ball moving. I can represent its movement by its motion trail (i.e the position of its center of gravity at any time) which describes exactly a curve -in dimension 3.

Now, when considering a human moving it’s somehow more complicated. When you are looking at your motion capture data, you mainly have the translation of your root (or hips) which is like the ball from the previous example, but on top of that you need to add the rotation of all the joints.

In that regard, you can see your pose as a high dimensional point: you just need to concatenate the translate of your root and the rotations of all your joints.
However, one important thing to remember when working with high dimensional data is that the way you represent your data matters, even though different these representations might seem strictly equivalent to you.
When applying Salient Poses, rather than concatenating the rotations of the joints, we concatenate their position in space. The main reason we do that is that it helps getting our high dimensional points homogeneous: we only have position informations and not a mix of position, angles or quaternions. There are other pros and cons that I will try to cover here (the article is not ready yet, so no link for now :p).
The error function
Another critical element of the algorithm is the error function. Basically the error function takes as argument a set of keyframes and will tell if reconstructing the animation using this set of keyframes will give a nice approximation of the original animation or not. If the value is low, it means that the set is good; if it is high, it means that the set is poorly chosen.
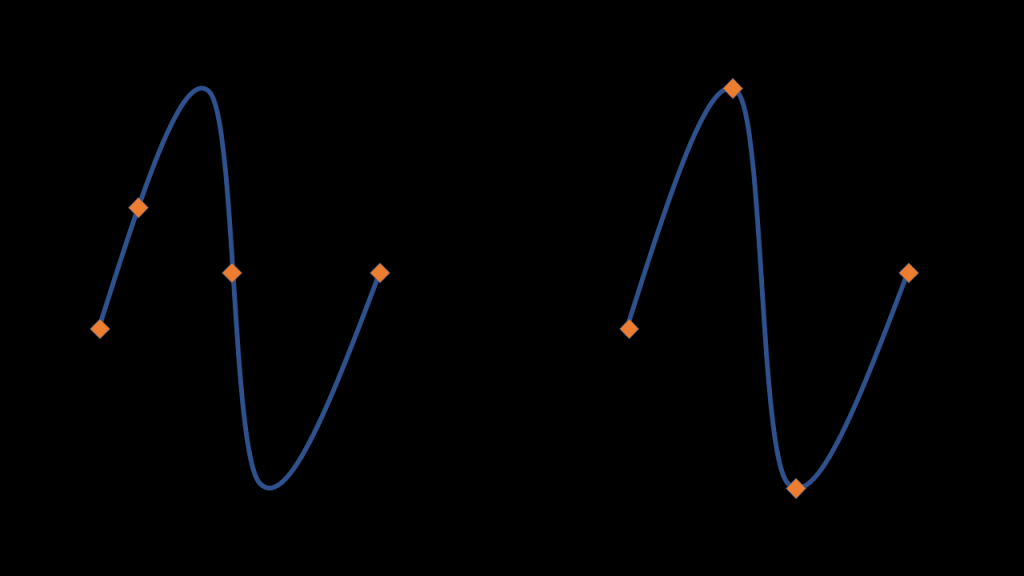
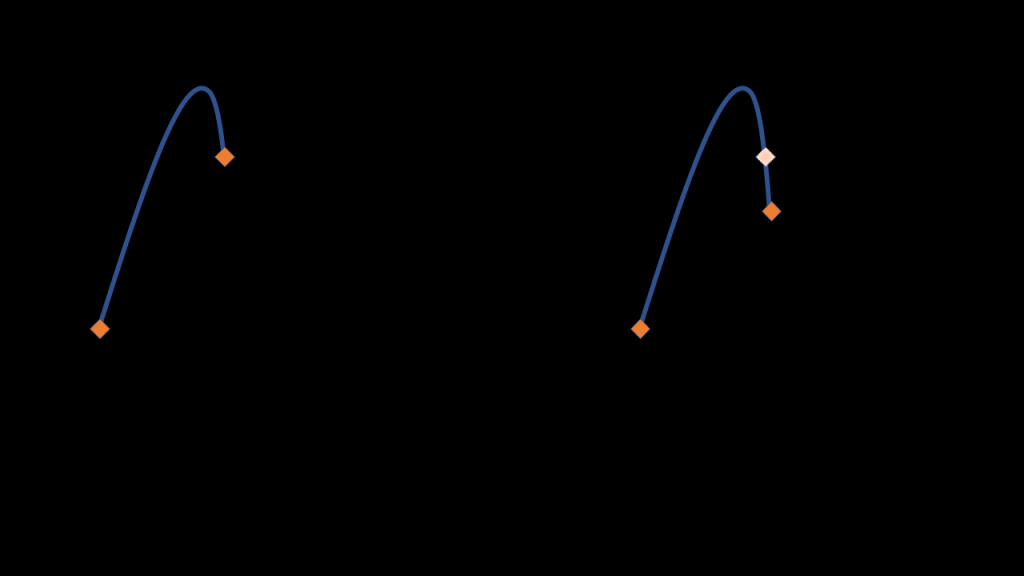
To compute this error function, the original paper proposes to linearly interpolate between the chosen keyframes then compute the maximum distance between the linearly interpolated curve and the original one.

Please keep in mind that this is a design choice that was selected ‘experimentally’ but might (and need to) be discussed.
The algorithm
First of all, let me state what the algorithm solves. Given an animation and an error function, the algorithm will compute the sets of k keyframes that minimize the error function for every k possible.
How do we solve that? Of course, we can go brute force and test all possible sets but that will obviously be pretty inefficient. Good thing is we can use Dynamic Programming to solve this problem! (Brute force is exponential complexity, DP lets us get polynomial!)
As a reminder -or not- Dynamic Programming is a method for solving optimization problems and relies on dividing the problem in smaller subproblems.
In our case, the smaller subproblem is solving the problem for animations of smaller size: the idea is that, if I know how to solve the problem for the animation cropped at frame F, then solving the problem for the animation cropped at frame (F+1) is easy!
For more details on how the algorithm performs at each iteration, please check the paper or this quick note I wrote for myself!
How do we use it?
The main use of Salient Poses is to implify Motion Capture datas. The main author implemented the algorithm into Maya: given an animation, it computes ‘quickly’ the optimal sets of keyframes. Then, the artist is free to check all those sets (there is some ghosting to display which poses would be chosen) then select the set that fits. The algorithm then performs simplification: it only keeps the keyframe of the chosen set and optimizes the tangents to keep an animation as close from the original as possible.

Discussion
There are really a lot of points that need to be discussed but I’ll give the most important ones here:
Evaluating: the main problem of this paper (and every single paper that covers keyframe animation to be honest) is the lack of metrics to evaluate properly the method. How can you say if a keyframe selection is good or not?
The error function: the paper proposes to compare the curve to the linear interpolation. It says that experimentally it gives better results than using spline interpolation or other interpolation method. However, once again, how can you evaluate properly the quality of these results?
The philosophy of the paper itself: so basically, the paper makes the initial assumption that the Salient Poses are the poses that would give a good interpolation. However this idea can be challenged as those two notions are from different scopes: Saliency relates to cognition when interpolation is more about computation. When you play a little bit with Salient Poses (I spent quite a few hours since I believe it is extremely interesting) you will notice that the algorithm will not necesarily pick the extremes, which is an heresy somehow. The reconstruction is still OK though, as it can use the tangents to optimize properly. So, we chose good poses for reconstruction but probably not Salient Poses in the end!
The good thing is, by playing on the error function, we can modify the criteria to have something more ‘topological’. The algorithm presented in the Salient Poses paper is powerful in the sense that it computes the optimal keyframe selection for the criteria that we proposed. However, it is up to us to provide a meaningful criteria.
There is still a lot of things to explore concerning this idea and, in my own opinion, I think there are extremely exciting ideas to develop. My first short paper (article incoming) proposes to use Salient Poses to solve some of its original flaws and my current work is still improving those results and giving them more interpretability!
